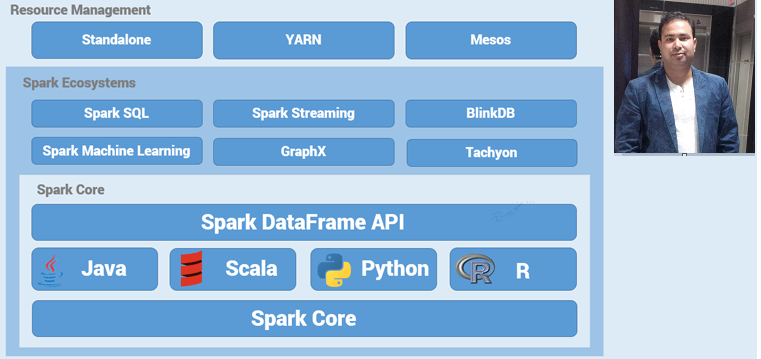
SPARK With SQL & HIVE

Let us first understand the importance of SparkSQL. It is a module of Spark that is used for structured data processing. The module is capable of acting as a distributed SQL query engine and provides a feature called DataFrames that provides programming abstraction. The module allows you to query structured data in programs of Spark by using SQL or a similar DataFrame API.
Spark SQL integrates relational processing with Spark’s functional programming. It provides support for various data sources and makes it possible to weave SQL queries with code transformations thus resulting in a very powerful tool.
Moreover, it can be used with different platforms such as Scala, Java, R, and Python. SQL and DataFrames provide a collective method for accessing multiple data sources, which include Avro, Hive, ORC, JSON, Parquet, and JDBC. Data can also be joined among these sources. For ETL and business intelligence tools, Spark offers industry standard ODBC and JDBC connectivity.
Let us explore, what Spark SQL has to offer. Spark SQL blurs the line between RDD and relational table. It offers much tighter integration between relational and procedural processing, through declarative DataFrame APIs which integrates with Spark code. It also provides higher optimization. DataFrame API and Datasets API are the ways to interact with Spark SQL.
With Spark SQL, Apache Spark is accessible to more users and improves optimization for the current ones. Spark SQL provides DataFrame APIs which perform relational operations on both external data sources and Spark’s built-in distributed collections. It introduces extensible optimizer called Catalyst as it helps in supporting a wide range of data sources and algorithms in Big-data.
In Sort,
- Spark SQL is a Spark module for structured data processing.
- An interface that provides more informartion about the stucture of data and computation being performed.
- Interacting with Spark SQl using: SQL
DataFrame API
Dataset API
with SPark SQl, we could execute quireis written using Basic SQl or HiveSQl.

Benefits of Spark SQL:
SparkSQL provides hive compatibility. It reuses the Hive metastore and frontend. Due to this, it is completely compatible with the existing Hive queries, UDFs, and data. To get benefitted with this feature, just install it with Hive. The image on the screen shows the interaction of these components. In addition, it mixes SQL queries with programs of Spark easily. For making queries fast, it also includes a cost-based optimizer, code generations, and columnar storage. Moreover, this module uses the Spark engine that allows it to scale to multi hour queries and thousands of nodes. This feature gives full mid-query fault tolerance. With this module, you do not need to use a different engine for the historical data
DataFrames:
Let us now understand the concept of dataframes. It is a distributed collection of data, in which data is organized into columns that are named. You can compare it with a data frame in R or Python or a table in a relational database, however with much richer optimization functionality. To construct a dataframe, you can use various sources like tables in Hive, structured data files, existing RDDs, and external databases. To convert them to RDDs, you can call the rdd method that returns the DataFrame content as an RDD of rows. The DataFrame API is available for different platforms like R, Scala, Python, and Java. Note that in prior versions of Spark SQL API, SchemaRDD has been renamed to DataFrame.
In Spark, a DataFrame is a distributed collection of data organized into named columns. Users can use DataFrame API to perform various relational operations on both external data sources and
Spark’s built-in distributed collections without providing specific procedures for processing data. Also, programs based on DataFrame API will be automatically optimized by Spark’s built-in optimizer, Catalyst.
DF can be constructed from:
- Structured Data file
- Tables in Hive
- External database
- Existing RDD
DataSet:A Dataset is a distributed collection of data. Dataset is a new interface added in Spark 1.6 that provides the benefits of RDDs (strong typing, ability to use powerful lambda functions) with the benefits of Spark SQL’s optimized execution engine. A Dataset can be constructed from JVM objects and then manipulated using functional transformations (map, flatMap, filter, etc.).
SQLContext:
The other component of SparkSQL is SQLContext. The SQLContext class or any of its descendants acts like the entry point into all functionalities. You just need a SparkContext to build a basic SQLContext. The code given on the screen shows how to create an SQLContext object. In addition, you can also build a HiveContext for availing the benefit of a superset of the basic SQLContext functionality. It also provides more features such as the writing ability for queries by using the more comprehensive HiveSQL parser. Other features are accessing Hive UDFs and the read data ability from Hive tables. The entire data sources that are available to an SQLContext still exist. Therefore, you do not require an existing Hive setup for using a HiveContext.
HiveContext:
HiveContext is just packaged separately for avoiding the dependencies of Hive in the default Spark build. For your applications, if these dependencies are not a concern, then HiveContext is recommended for Spark 1.3. The future releases will be focused on getting SQLContext up to feature parity with a HiveContext. You can also use the spark.sql.dialect option to select the specific variant of SQL, which is used for parsing queries. To change this parameter, you can use the SET key=value command in SQL or the setConf method on an SQLContext. The only dialect available for an SQLContext is “sql” that makes use of a simple SQL parser. However, in a HiveContext, the default is “hiveql”, which is much more comprehensive. Therefore, it is recommended for most use cases. On an SQLContext, the sql function allows applications to programmatically run SQL queries and then return a DataFrame as a result. The code given on the screen shows the use of the sql function.
*SQLContext is the entry point for all SPARK SQL functionlaity.
To create a basic SQLConetext, all you need is a SparkConext
// sc is existing SparkContext
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
*HiveContext provides superset of functionality over SQLContext.
val hiveContext = new org.apache.spark.sql.hive.HiveContext(sc)
Creating DataFrames:
With SQLContext, applications can create DataFrames from an existing RDD, from a Hive table or from datasources.
val list = sc.parallelize(1 to 10)
val df1 =list.map(x=>(x,x*2)0.toDF("single","double")
val a =List(("ironman",3),("Hero,4),("DDLJ",5))
val ratings = a.toDF("movie","rating")
Example :
//Lets load Employe record file having EmpID,Name,Salary fields
val emp = sc.textFile("/user/cloudera/sparklab/emp")
emp: org.apache.spark.rdd.RDD[String] = /user/cloudera/sparklab/emp MapPartitionsRDD[7] at textFile at <console>:27
//Creating case class so that we can give schema to above RDD
case class clsEmp(id:Int,name:String,sal:Int)
//Applying Schema to emp RDD
val empRec = emp.map(x=>{
| val y = x.split(" ")
| clsEmp(y(0).toInt,y(1),y(2).toInt)})
empRec: org.apache.spark.rdd.RDD[clsEmp] = MapPartitionsRDD[8] at map at <console>:31
//converting RDD to DF using toDF function
val df = empRec.toDF
df: org.apache.spark.sql.DataFrame = [id: int, name: string, sal: int]
//You can extract rows by using below select query in DataFrame itself
df.select("id","name","sal").show
//Using SPARK SQL usery
//First register the above DF as temp Table
DF.registerTempTable("Employee");
//Queries to Employee table
val Result = sqlContext.sql("select * from Employee");
------------------------------------------------------
List of Functions used for DataFrame:
------------------------------------------------------
Select:
--------
--------
Selects a set of columns. This is a variant of select that can only select existing columns using column names (i.e. cannot construct expressions).
df.select("id","name","sal").show
selectExpr:
-------------
-------------
Selects a set of SQL expressions. This is a variant of select that accepts SQL expressions.
df.selectExpr("colA", "colB as newName", "abs(colC)")
groupBy:
------------
------------
Groups the DataFrame using the specified columns, so we can run aggregation on them. See GroupedData for all the available aggregate functions.
// Compute the average for all numeric columns grouped by department.
df.groupBy($"department").avg()
// Compute the max age and average salary, grouped by department and gender.
df.groupBy($"department", $"gender").agg(Map(
"salary" -> "avg",
"age" -> "max"
))
rollup:
--------
--------
Create a multi-dimensional rollup for the current DataFrame using the specified columns, so we can run aggregation on them. See GroupedData for all the available aggregate functions.
// Compute the average for all numeric columns rolluped by department and group.
df.rollup($"department", $"group").avg()
// Compute the max age and average salary, rolluped by department and gender.
df.rollup($"department", $"gender").agg(Map(
"salary" -> "avg",
"age" -> "max"
))
cube:
-------
-------
Create a multi-dimensional cube for the current DataFrame using the specified columns, so we can run aggregation on them. See GroupedData for all the available aggregate functions.
// Compute the average for all numeric columns cubed by department and group.
df.cube($"department", $"group").avg()
// Compute the max age and average salary, cubed by department and gender.
df.cube($"department", $"gender").agg(Map(
"salary" -> "avg",
"age" -> "max"
))
agg:
------
------
Aggregates on the entire DataFrame without groups.
// df.agg(...) is a shorthand for df.groupBy().agg(...)
df.agg(max($"age"), avg($"salary"))
df.groupBy().agg(max($"age"), avg($"salary"))
describe:
-----------
-----------
Computes statistics for numeric columns, including count, mean, stddev, min, and max. If no columns are given, this function computes statistics for all numerical columns.
This function is meant for exploratory data analysis, as we make no guarantee about the backward compatibility of the schema of the resulting DataFrame. If you want to programmatically compute summary statistics, use the agg function instead.
df.describe("age", "height").show()
toDF:
-------
-------
Returns a new DataFrame with columns renamed. This can be quite convenient in conversion from a RDD of tuples into a DataFrame with meaningful names. For example:
val rdd: RDD[(Int, String)] = ...
rdd.toDF() // this implicit conversion creates a DataFrame with column name _1 and _2
rdd.toDF("id", "name") // this creates a DataFrame with column name "id" and "name"
na:
----
----
Returns a DataFrameNaFunctions for working with missing data.
// Dropping rows containing any null values.
df.na.drop()
stat:
------
------
Returns a DataFrameStatFunctions for working statistic functions support.
// Finding frequent items in column with name 'a'.
df.stat.freqItems(Seq("a"))
join:
------
------
Inner equi-join with another DataFrame using the given column.
Different from other join functions, the join column will only appear once in the output, i.e. similar to SQL's JOIN USING syntax.
// Joining df1 and df2 using the column "user_id"
df1.join(df2, "user_id")
// Joining df1 and df2 using the columns "user_id" and "user_name"
df1.join(df2, Seq("user_id", "user_name"))
or equivalent
df1.join(df2).where($"df1Key" === $"df2Key")
Note that if you perform a self-join using this function without aliasing the input DataFrames, you will NOT be able to reference any columns after the join, since there is no way to disambiguate which side of the join you would like to reference.
sort:
------
------
Returns a new DataFrame sorted by the specified column, all in ascending order.
df.sort($"col1", $"col2".desc)
orderBy:
-----------
-----------
Returns a new DataFrame sorted by the given expressions. This is an alias of the sort function
filter:
-------
-------
Filters rows using the given condition.
df.filter("sal > 30")
peopleDf.filter($"age" > 15)
peopleDf.where($"age" > 15)
limit:
------
------
Returns a new DataFrame by taking the first n rows. The difference between this function and head is that head returns an array while limit returns a new DataFrame.
unionAll:
-----------
-----------
Returns a new DataFrame containing union of rows in this frame and another frame. This is equivalent to UNION ALL in SQL.
intersect:
------------
------------
Returns a new DataFrame containing rows only in both this frame and another frame. This is equivalent to INTERSECT in SQL.
except:
---------
---------
Returns a new DataFrame containing rows in this frame but not in another frame. This is equivalent to EXCEPT in SQL.
sample:
---------
---------
Returns a new DataFrame by sampling a fraction of rows.
Parameters:
withReplacement - Sample with replacement or not.
fraction - Fraction of rows to generate.
seed - Seed
randomSplit:
----------------
----------------
Randomly splits this DataFrame with the provided weights.
Parameters:
weights - weights for splits, will be normalized if they don't sum to 1.
seed - Seed for sampling.
explode:
----------
----------
Scala-specific) Returns a new DataFrame where each row has been expanded to zero or more rows by the provided function. This is similar to a LATERAL VIEW in HiveQL. The columns of the input row are implicitly joined with each row that is output by the function.
The following example uses this function to count the number of books which contain a given word:
.....................................................................................................................................
case class Book(title: String, words: String)
val df: RDD[Book]
case class Word(word: String)
val allWords = df.explode('words) {
case Row(words: String) => words.split(" ").map(Word(_))
}
val bookCountPerWord = allWords.groupBy("word").agg(countDistinct("title"))
........................................................................................................................................
df.explode("words", "word"){words: String => words.split(" ")}
dropDuplicates:
--------------------
Returns a new DataFrame that contains only the unique rows from this DataFrame. This is an alias for distinct.
Returns a new DataFrame that contains only the unique rows from this DataFrame. This is an alias for distinct.
head:
------
------
Returns the first n rows.
first:
------
------
Returns the first row. Alias for head().
registerTempTable:
-----------------------
-----------------------
Registers this DataFrame as a temporary table using the given name. The lifetime of this temporary table is tied to the SQLContext that was used to create this DataFrame.
Reading JSON Files :
//example 1 - simple json
val persons = sqlContext.read.json("people.json")
persons.registerTempTable("persons")
sqlContext.sql("select * from persons").show
//example2 -Nested JSON
val employees_df = sqlContext.read.json("us_states.json")
employees_df.registerTempTable("employees")
sqlContext.sql("select id,name,salary,address.city,address.country from employees").show
//To read csv files you need to restart your spark-shell with the below given arguments
//Dealing with xml files:
//to read xml files you need to restart your spark-shell with the below given arguments
//follw below github page for detailed package info - https://github.com/databricks/spark-xml
spark-shell --packages com.databricks:spark-xml_2.10:0.4.1
import org.apache.spark.sql.hive.HiveContext
import org.apache.spark.sql.SQLContext
import org.apache.spark.sql.SaveMode
val conf = new SparkConf().setMaster("local").setAppName("HiveContext")
val sc = new SparkContext(conf);
val hiveContext:SQLContext = new HiveContext(sc)
//configuring it with Hive metastore
hiveContext.setConf("hive.metastore.uris","thrift://localhost:9083")
hiveContext.tables("default").show
//Using this Hive Context ,create table in Hive using any file
//Loading reocrd from list into Hive table
val lstName = List(("100","Merry"),("101","Lucy"))
val nameDF = lstName.toDF("id","name")
namedf.write.format("orc").mode(SaveMode.Append).saveAsTable("tblBabyNames")
//Reading Hive Table from HiveContext
val baby_namesdf = hiveContext.table("baby_names")
baby_namesdf.registerTempTable("baby_names")
hiveContext.sql("select * from baby_names").show
//example 1 - simple json
val persons = sqlContext.read.json("people.json")
persons.registerTempTable("persons")
sqlContext.sql("select * from persons").show
//example2 -Nested JSON
val employees_df = sqlContext.read.json("us_states.json")
employees_df.registerTempTable("employees")
sqlContext.sql("select id,name,salary,address.city,address.country from employees").show
//Writing dataframe data as jason file
baby_names_df.write.json("/user/cloudera/parquet-to-json")
//To read csv files you need to restart your spark-shell with the below given arguments
// follow below github page for detailed package info- https://github.com/databricks/spark-csv
spark-shell --packages com.databricks:spark-csv_2.11:1.5.0
val csvfile = sqlContext.read.format("com.databricks.spark.csv").option("header","true").option("inferSchema", "true").option("delimiter",",").load("1800.csv")
//Dealing with xml files:
//to read xml files you need to restart your spark-shell with the below given arguments
//follw below github page for detailed package info - https://github.com/databricks/spark-xml
spark-shell --packages com.databricks:spark-xml_2.10:0.4.1
val employees_df = sqlContext.read.format("com.databricks.spark.xml").option("inferSchema", "true").option("rootTag","employees").option("rowTag", "employee" ).load("input/employees.xml")
val emp_dataNormal = employees_df.select("emp_no","emp_name","address.city","address.country","address.pincode","salary","dept_no").show
//dealing parquet files
val baby_names_df = sqlContext.read.parquet("baby_names.parquet")
//Now as data is loaded to above dataframe , use it as normal dataframe now and can apply all operations.
//Now as data is loaded to above dataframe , use it as normal dataframe now and can apply all operations.
SPARK- Hive SQL:Lets learns here how to work with Hive using Spark.
/Creating HiveContext [Stop your sc using sc.stop (in case if you are in spark-shell)]
import org.apache.spark.{SparkContext,SparkConf}import org.apache.spark.sql.hive.HiveContext
import org.apache.spark.sql.SQLContext
import org.apache.spark.sql.SaveMode
val conf = new SparkConf().setMaster("local").setAppName("HiveContext")
val sc = new SparkContext(conf);
val hiveContext:SQLContext = new HiveContext(sc)
//configuring it with Hive metastore
hiveContext.setConf("hive.metastore.uris","thrift://localhost:9083")
hiveContext.tables("default").show
//Using this Hive Context ,create table in Hive using any file
hiveContext.sql("use default")
val baby_namesdf = hiveContext.read.parquet("baby_names.parquet") baby_namesdf.write.format("orc").mode(SaveMode.Append).saveAsTable("tblBabyNames)
val lstName = List(("100","Merry"),("101","Lucy"))
val nameDF = lstName.toDF("id","name")
namedf.write.format("orc").mode(SaveMode.Append).saveAsTable("tblBabyNames")
//Reading Hive Table from HiveContext
val baby_namesdf = hiveContext.table("baby_names")
baby_namesdf.registerTempTable("baby_names")
hiveContext.sql("select * from baby_names").show
//Accessing MySQL database through shell:
//command to login mysql in cloudera vm
mysql -uroot -pcloudera
//or in cloud-xlab enviornment
mysql -h ip-172-31-13-154 -usqoopuser -pNHkkPnn876rp
mysql>show databases;
mysql > use retail_db;
mysql>show tables;
//Reading JDBC Tables :
//Reading Mysql Tables
while reading jdbc tables make sure that concern jdbc jar should be added to spark-class path use below arguments to add jar while starting your spark-shell
spark-shell --jars </path/to/jar>
val prop = new java.util.Properties
prop.put("user","root")
prop.put("password","cloudera")
prop.put("driverClass","com.mysql.jdbc.Driver")
val uri = "jdbc:mysql://localhost:3306/retail_db"
val table = "orders"
val empDF = hiveContextContext.read.jdbc(uri,table,prop)
empDF.registerTempTable("customers")
hiveContext.sql("select * from customers").show
//writing Dataframe to JDBC
//Create a Dataframe
val table ="baby_names"
val baby_namesdf = hiveContext.read.parquet("/user/cloudera/datasets/ baby_names.parquet")
or
val baby_namesdf = (List(("111","aahana")).toDF
baby_namesdf.write.jdbc(uri,table,prop)
Sample BigData-Spark Project done by using Spark-Core/SQL:
Project-1 :
Project-2:
Comments
Post a Comment