SPARK with Machine Learning

BigData Project List
Note: This Bog is in progress and will be updated soon with detailed ML algorithims and samlpe projects.Spark MLlib is Apache Spark’s Machine Learning component. One of the major attractions of Spark is the ability to scale computation massively, and that is exactly what you need for machine learning algorithms.
Machine learning is closely related to computational statistics, which also focuses on prediction-making through the use of computers.
ML is an approach of how to train the applications(Modele)
There are three categories of Machine learning tasks:
- Supervised Learning: Supervised learning is where you have input variables (x) and an output variable (Y) and you use an algorithm to learn the mapping function from the input to the output.
in other way, you can say, If you train your model by using input values (called as input features in ML) and output value (called as label variable in ML) for the feature, that approach is called Supervised Learning.
Example: Suppose you have to predict Cholesterol level of patients based on their Height and Weight input.
For this we need to have a data-set which has Height,Weight and Cholesterol data for many existing patients.We have to pass this data-set to one of the Supervised algorithm which will find the patterns from given set of data and this knowledge (obtained from existing patterns) is called model fit which can be used to predict the Cholesterol level for new patients. - Unsupervised Learning: Unsupervised learning is a type of machine learning algorithm used to draw inferences from datasets consisting of input data without labeled responses.
- Reinforcement Learning: A computer program interacts with a dynamic environment in which it must perform a certain goal (such as driving a vehicle or playing a game against an opponent). The program is provided feedback in terms of rewards and punishments as it navigates its problem space. This concept is called reinforcement learning.

Supervised Learning Train set: is a rich set of examples to train the model.Each example should containinput features and label.The label can be continues or a classifier.
If Model is Regression,Label is continuous.
exp: suppose Age , Height,Weight is as input feature in dataset and Cholesterol is label.As cholestorl variable is a continuous value, we will use regression model.
If Model is classification algorithm, the label should be any one of given option(called as Classifiers)
exp: suppose Age , Height,Weight is as input feature in dataset and IsDiabltic is label.As IsDiabltic variable is a classified value(yes/No), we will use Classification model.
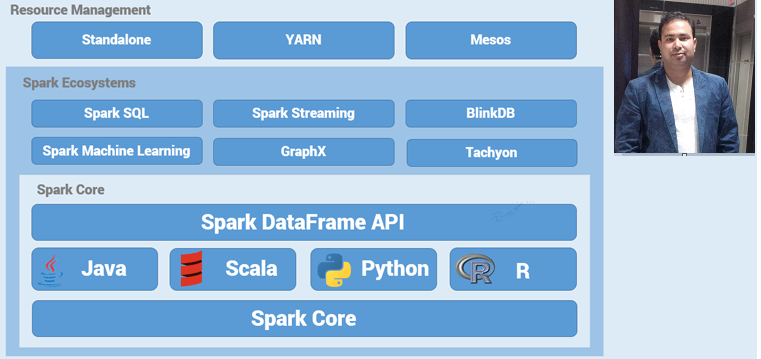
Spark MLlib Tools
Spark MLlib provides the following tools:
- ML Algorithms: ML Algorithms form the core of MLlib. These include common learning algorithms such as classification, regression, clustering and collaborative filtering.
- Featurization: Featurization includes feature extraction, transformation, dimensionality reduction and selection.
- Pipelines: Pipelines provide tools for constructing, evaluating and tuning ML Pipelines.
- Persistence: Persistence helps in saving and loading algorithms, models and Pipelines.
- Utilities: Utilities for linear algebra, statistics and data handling.
Life Cycle of Machine Learning ::

1- Data Extraction: Very first step in writing Machine Learning application/Model , we need data and data can be extracted in different ways..lets understand few ways to get data.
- Extracting Social Media data
- Extracting data from RDBMS systems
- Extracting data from NOSQL databases(i.e MongoDB,HBase,Casandra..)
- Extracting data from streaming sources(i.e Censor data , Live cams,Logs)
- Extracting data from files
- Extracting data though web scrapping
ETL tools, Haddop(KAFKA/FLUME/SQOOP) ,IOT such things are used in above data engineering activities.
2- Data Cleansing: Once we get data, we have to make sure that data is realy in good shape which can be used for our model.Here are few way to clean the data.
- Data De-duplication(Elimination of duplicates)
- Cleaning Nulls(Cleaning missing/Nulls values)
Also for your model, some input variables may be fit and some other may not be fit.In such cases, we need to transform unfit variable to fit variable.
Exp: As we know that Regression algorithm need all the input features as continuous values only but what if your data set has few input features as Classifiers as well then we have to transform these classifier variables into continuous variables..suppose you have Qualification(with value as MTec,BTec,PHD,..) as input feature along with other continous variable.here we have to consider some score against each type of qualification so that we can have number values in this input feature.
Exp: As we know that Regression algorithm need all the input features as continuous values only but what if your data set has few input features as Classifiers as well then we have to transform these classifier variables into continuous variables..suppose you have Qualification(with value as MTec,BTec,PHD,..) as input feature along with other continous variable.here we have to consider some score against each type of qualification so that we can have number values in this input feature.
MTech -- 8
BTec -- 7
PHD -- 9
Others -- 5
or in some cases you need to convert continuous to classified values..then based on your domain understanding/demand, you can convert..suppose we have Sachin's each inning score as continous variable in our dataset ...here we can find Average of all innings and can classify each inning score as Above average or below average.
Score ---- Converted Classified value
90 ----- Above Avg
40 ----- Below Avg
20 ----- Below Avg
85 ----- Above Avg
113 ------ Above Avg
3-Data Preparation: Data is split usually into 2 sets. Training Set and Testing Set.Lets go through few suggestions which we should consider while data preparations.
- Provide as many as possible input examples so that,Model can learn more patterns from data.
- Do'nt keep all data into training set.keep around 70-80% of total data into training set.
- Keep remaining 20-30% data into testing set.
- Before training the model , shuffle the training set to reduce over-fitting problems.
- Normalise the variables
- Reduce dimensionalilty - If input feature are thousands, model will be confusing.if there are some features which are not impacting or less impacting the target variable,such variables need to be eliminated from train set and tests.
- If data is unstructured text , we need to extract features from text.
ex: Word proportion feature
Word frequency feature
Word existence feature
................................
TF-IDF feature
4-Model Selection:
- If data volume is Small : Apply all possible model on the training set and test accuracy with test set. Now select the model which has given the most accuracy among all model tested.
- If data volume is Bigger:Only for model selection, we can not use entire terabytes of data.
In such cases, take 20-30% of random sample from the given data and divide this dataset as PreTrain Set and PreTest set.
Apply all possible models on PreTrain set and test accuracy using PreTest set
ex: Model1 => 70 % accuracy
Model2 => 90% accuracy
Model3 => 85 % accuracy
Here if we see that our given data is best fit to model2.So we can train this model2 with original data.
5- Train the Model:Once model got trained, model will extract proper parameters based patterns existed in data towards prediction.This is simply called "Knowledge of the model".In ML term, the knowledge obtained by model is called ModelFit.
This modelfit may not be perfect so we may need to fine tune the parameters.
6-Test the accuracy of Models: If accuracy of model is more than expected accuracy then we can approve the model.
7-Deploying the Model: Once the accuracy is approved,
- If application is online(real time),need to deploy parameters of model fit into the application
- If application is batch , keep all predictable data into one file and submit the file to model fit.
8-Rebuild the Model:Once model got deployed, in beginning few days, its predictions are good in reality.But after days passing, predictions accuracy will be decreasing.Because of, as new data is coming into organisation, there is chance of new patterns.
These new patterns are unknown to deployed model so by clubing old/new data ,, we need to train model again.
These new patterns are unknown to deployed model so by clubing old/new data ,, we need to train model again.
If necessary , we may need to change the model if new coming data is not following similar pattern( may be existing data was following some type pattern(linear pattern) but may be new data is following different pattern(non-linear pattern) ).
This process is called re-building the model.In AI , this rebuilding happens automaticaly.
This process is called re-building the model.In AI , this rebuilding happens automaticaly.
Comments
Post a Comment