Analysis on Movie Rating DataSet Using Spark Core/SQL

Project Introduction:
Domain - Entertainment
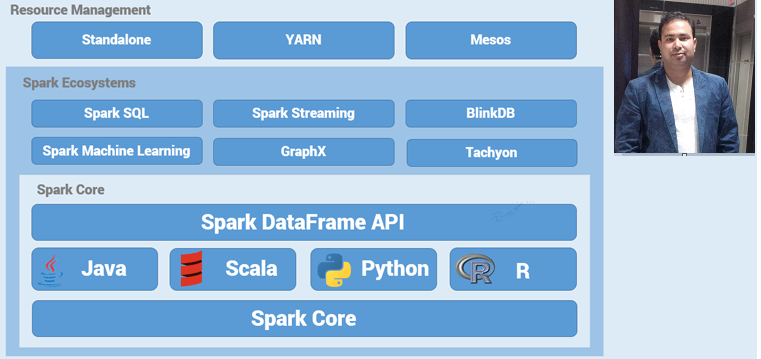
Technology Use - SPARK CORE/SQL (using scala)
DataSet - movies.dat , ratings.dat , users.dat (DataSet Link: https://drive.google.com/open?id=1ovZIzQ9p4sKgLQE_ka8RO6kGezYk9wU1)
These files contain 1,000,209 anonymous ratings of approximately 3,900 movies made by 6,040 MovieLens users who joined MovieLens in 2000.
RATINGS FILE DESCRIPTION:All ratings are contained in the file "ratings.dat" and are in the following format: UserID :: MovieID :: Rating :: Timestamp - UserIDs range between 1 and 6040 - MovieIDs range between 1 and 3952 - Ratings are made on a 5-star scale (whole-star ratings only) - Timestamp is represented in seconds since the epoch as returned by time(2) - Each user has at least 20 ratings
MOVIES FILE DESCRIPTION:Movie information is in the file "movies.dat" and is in the following format: MovieID :: Title :: Genres - Titles are identical to titles provided by the IMDB (including year of release) - Genres are pipe-separated and are selected from the following genres: * Action , * Adventure, * Animation, * Children's, * Comedy, * Crime, * Documentary, * Drama, * Fantasy, * Film-Noir, * Horror, * Musical, * Mystery, * Romance, * Sci-Fi, * Thriller, * War, * Western
USERS FILE DESCRIPTION:User information is in the file "users.dat" and is in the following format: UserID::Gender::Age::Occupation::Zip-code Gender is denoted by a "M" for male and "F" for female.Age is chosen from the following ranges: * 1: "Under 18" * 18: "18-24" * 25: "25-34" * 35: "35-44" * 45: "45-49" * 50: "50-55" * 56: "56+" Occupation is chosen from the following choices: 0: "other" or not specified , 1: "academic/educator" , 2: "artist" 3: "clerical/admin" , 4: "college/grad student", 5: "customer service" 6: "doctor/health care" , 7: "executive/managerial" , 8: "farmer", 9: "homemaker" , 10: "K-12 student", 11: "lawyer", 12: "programmer" 13: "retired" , 14: "sales/marketing", 15: "scientist", 16: "self-employed" 17: "technician/engineer", 18: "tradesman/craftsman", 19: "unemployed"
Lets write some Spark SQL code to analyse this data.Lets use Scala shell to write this code.
// Load all 3 files into RDD"rawMovies " ,"rawRatings " ,"rawUsers "val rawMovies = sc.textFile("movies.dat");
val rawRatings = sc.textFile("ratings.dat");
val rawUsers = sc.textFile("users.dat");
//Create case class for creating schema for all above RDD's
case class clsMovies(movieID:Int,title:String, genres:String);
case class clsRatings(userid:Int,movieID:Int,rating:Int,timestamp:String);
case class clsUser(userid:Int,gender:String,age:Int,occupation:Int,zipcode:String);
//Transforming above RDD's to DataFrame using above schema and register as Temp table.
val moviesWithSchema = rawMovies.map(x=>x.split("::")).map(x=>clsMovies(x(0).toInt,x(1),x(2)));
val moviesDF = moviesWithSchema .toDF;
moviesDF.registerTempTable("movies");
val ratingsWithSchema = rawRatings.map(x=>x.split("::")).map(x=> clsRatings(x(0).toInt,x(1).toInt, x(2).toInt,x(3)));
val ratingsDF = ratingsWithSchema .toDF;
ratingsDF.registerTempTable("ratings");
val usersWithSchema = rawUsers.map(x=>x.split("::")).map(x=> clsUser(x(0).toInt,x(1),x(2).toInt, x(3).toInt,x(4)));
val usersDF = usersWithSchema .toDF;
usersDF.registerTempTable("users");
Q-1) Find out the animated movies that are rated 4 or above:
val q1res=sqlContext.sql("select m.title,r.rating,m.genres from movies m inner join ratings r on m.movieID =r.movieID and r.rating >=4 and genres='Animation' ");
q1res.show()
Result: This is partial result showing only first 20 rows.
Q-2) Detect the gender bias on movie ratings for a genres:
val q2res1 = sqlContext.sql("select m.movieID,m.genres,r.userid,r.rating from movies m inner join ratings r on m.movieID =r.movieID ");
val q2myres1= q2res1.withColumn("genres", explode(split($"genres", "\\|")))
q2myres1.registerTempTable("tblMovRating");
val q2res2 = sqlContext.sql("select tmr.movieID,tmr.genres,tmr.rating,u.gender from tblMovRating tmr inner join users u on tmr.userid =u.userid ");
q2res2.registerTempTable("tblMovRatingfinal");
val q2finalResult = sqlContext.sql("select genres,round((sum(case when gender='M' then rating end) /count(case when gender='M' then 1 end) ),2) as male_rating,round((sum(case when gender='F' then rating end) /count(case when gender='F' then 1 end)),2 ) as Female_rating from tblMovRatingfinal group by genres order by genres desc");
q2finalResult.show();
Q-3) Group the ratings by age:
val q3res1 = sqlContext.sql("select u.age,r.rating from users u inner join ratings r on u.userid = r.userid ");
q3res1.registerTempTable("tblMovRatingByAge");
val q3res2 = sqlContext.sql("select age,round(avg(rating),2)as Avg_rating from tblMovRatingByAge group by age order by age asc");
q3res2.show();
Q-4) Find out the average rating for movies:
val q4res1 = sqlContext.sql("select m.title,r.rating from movies m inner join ratings r on m.movieID =r.movieID ");
q4res1.registerTempTable("tblAvgMovRating");
val q4finalResult = sqlContext.sql(" select title , round(avg(rating),2) as AvgRating from tblAvgMovRating group by title order by AvgRating desc");
q4finalResult .show();
Result: This is partial result showing only first 20 rows.
Q-5) Find out the titles of the best rated movies:
val q5res1 = q4finalResult.toDF;
val q5finalResult=q5res1.filter($"AvgRating" === 5);
q5finalResult.select("title","AvgRating").show();
Result:
Note: You can download this dataset from above given link and follow all the above command and you can get full results and even can do more different other analysis on this dataset.
Excellent Blog, I like your blog and It is very informative. Thank you
ReplyDeletePyspark online Training
Learn Pyspark Online